【Python】dfplyを用いたpandasデータフレームのデータ抽出
CSVファイルなどで用意されたデータをpandasで取り込んだ後、特定の条件に当てはまるデータを抽出して集計などを行いたかったのですが、複合条件をサクサク書いて試行錯誤しやすような方法が欲しかったのです。
例えば「"20代"の"A市"に住んでいる"男性"で、"**線"に乗って通勤している"会社員"」のような、複数列で属性を管理しているテーブルで、該当しそうな条件を複数組み合わせてターゲットを絞り込んでいくようなイメージです。
もちろんデータベースに突っ込んで、SQLで書けばちょちょいと出来てしまいような雰囲気もありますが、そのようなクエリーが書けるとか準じたフィルター機能を持っているライブラリーとか無いかと探していて見つけたのが、タイトルにも入れたdfplyでした。
インストール
Windows10環境のAnaconda(64bit版) 3.7系の環境に入れました。他の環境は利用されるパッケージインストーラーなどに読み替えてみてださい。結論から言うとAnaconda Navigatorやcondaでは入れられませんでした。
pipを使えば入るので、いろいろと面倒な事をやりたくなければ、仮想環境を作ってそこで
pip install dfply
でよろしいのではないかと。(condaとpipを混ぜると危険という説もありますので、ご利用は慎重に)ちなみにPython2系はサポートしていないようです。
データ操作
基本的には " >>"でデータパイプラインをつなぎ、"X"を用いて列を参照します。
まずは必要なライブラリーを用意し、適当なテストデータを用意します。ここではみんな大好き"Iris"を使ってみます。(seabornがanacondaにデフォルトでインストールされていなかったので、不足エラーが出た場合には別途にcondaコマンドなりAnaconda Navigatorを使ってインストールしてください)
import pandas as pd
import numpy as np
from dfply import *
import seaborn as sns
iris = sns.load_dataset('iris')
print(iris.head())
print(type(iris))
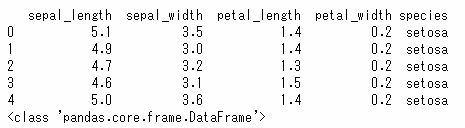
“>>"を使った接続方法として、head()につないでみます。
iris >> head()

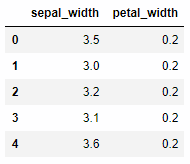
特定の列を表示するには select を使います。列の参照には “X". 列名を使います。
iris >> select(X.sepal_width, X.petal_width) >> head()
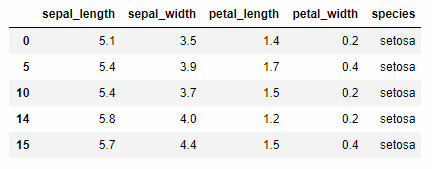
特定の条件で行の絞り込みを行います。ここでは maskを使い、sepal_length が5以上、sepal_widthが3以上のものを選択します。
iris >> mask(X.sepal_length > 5, X.sepal_width > 3) >> head()
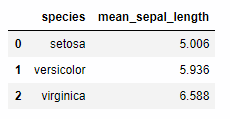
species毎のsepal_lengthの平均値を集計します。group_by で集計をかけ、mean()で平均を取ります。
iris >> group_by(X.species) >> summarize(mean_sepal_length = X.sepal_length.mean())
特定の条件を持つ行だけを抽出する場合は filter_by を使います。speciesが"versicolor"の、petal_length, petal_widthを表示します。
iris >> filter_by(X.species == "versicolor") >> select(X.petal_length, X.petal_width) >> head()
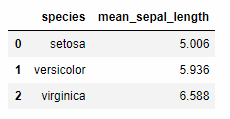
このように操作関数を利用して、データをフィルターしたり加工することが出来ます。上記以外にも多くの関数が用意されていますので、必要に応じて以下の配布元のgithubを参照されると良いでしょう。
https://github.com/kieferk/dfply