AWS RDS PostgreSQLからRedshiftにデータ移行する際にハマった点
集計データをAWSのデータベースサービスのRDS PostgreSQLに構築していたのですが、どうにもパフォーマンスが上がらないためRedshiftを試してみようという事になり、データを移行しようと試みたのですが、「お前は初心者か!」といったレベルのものから、どうにも理由が分からない挙動を含めて難儀したのでメモっておきます。(Redshiftに触るのも久々だったというのもある。)
前提としてはRDS上に作られたテーブルをそのまま持っていくのと、事前にSQLで処理した形でテーブルの構造を変えて持っていくものがあります。両者の集計のパフォーマンスの差を見たかったのですね。
テーブルを移行するならDatabase Migration Service(DMS)で一発
Redshiftにデータを入れるためには、S3にファイルを用意してCopyコマンドで流し込むといったやり方が多いかと思うのですが、テーブルが大量にある場合には面倒です。今回はDMSを使いました。
ここではレプリケーション用のインスタンスを立てて、エンドポイントとしてソースをRDS、ターゲットをRedshiftに設定します。
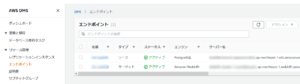
あとはデータベース移行タスクを作って、フルロードで流し込んでいけば良いのです。
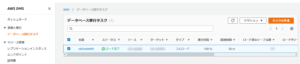
進行状況をモニターしていて100%になれば成功。
レプリケーションインスタンスをケチってt2.microにしていたら、メモリー不足でエラーになりアップグレードして再実行したりもしましたが、概ね問題なく移行できました。これは自分でEC2立てて中継スクリプトを書くことを考えると楽ちんでしょう。
加工するなら中継サーバーが必要
おそらくはRDSのselectの出力をS3に投げ込める関数とかあるんじゃないかなあと甘い期待をもっていたのですが、どうやら無さそうです。"\o ファイル名"コマンドの出力先でS3を指定できるとか、なんかこんな感じの事が出来ればベストだったのですが見つけられませんでした。
そうなれば一旦ディスクに入れるしかないので、中継用のEC2を立ててそこからDBにアクセスするようにします。ちなみにRDS側のPostgreSQLをVer11にすると、中継サーバーのEC2のディストリビューション/バージョンによっては、psqlが古いバージョンのものしか入らない場合があります。アクセスしようとするとバージョン不整合で怒られて、yumとかaptしようとするとVer11が標準では入ってなくてリポジトリ―追加など一手間かかります。この辺が面倒な人はRDS側は枯れたバージョンで動かしておく方が吉でしょうw
データ抜き取り用のSQLを書いて、extract.sqlファイルに保存したとして、次のにCSVファイルを作る事が出来ます。
psql -h (RDSのエンドポイント)-U (ユーザー名)(DB名) -A -F, -t < extract.sql > output.csv</code> -A: 行揃え無しのテーブル出力 -F:行揃え無しのフィールド出力区切り文字 -t:行のみを表示
-F の後にスペースを入れて , を付けるとエラーになりました。-F, と続けて書かないとダメっぽいです。
また上の例の"output.csv"中に半角英数以外の文字が含まれる場合はUTF-8に変換しておいた方が良いでしょう。
またsqlの出力結果のファイルの最後に出力行数として "(** rows)"が付いている場合もあります。このままRedshiftに流し込むと、"Delimiter文字が見つからない”などとエラーになるので削除します。
このファイルをS3バケツに転送してCopyコマンドでロードしていきます。コマンド自体はRedshiftの"Query editor"からも投入できますし、"SQL Workbench"などのツールを使っても実行できます。
ここから結構、試行錯誤が続いたのですが、以下のようなオプションでうまくいきました。
COPY (テーブル名)FROM 's3://(バケツのパス)/CSVファイル名’CREDENTIALS 'aws_access_key_id=(S3のアクセスキー);aws_secret_access_key=(S3の秘密キー)’delimiter ',’null as '\000’gzip;
[Amazon](500310) Invalid operation: Load into table 'answer_24509’ failed. Check 'stl_load_errors’ system table for details.;
SELECT starttime, TRIM(colname), err_code, TRIM(err_reason)FROM stl_load_errorsORDER BY starttime DESC LIMIT 5;