Pycaretで時系列処理を行う際の、欠測データの扱いの備忘録
学習過程において、いろいろな前処理をよしなに行ってくれるPycaretは大変便利なのですが、データが欠測している場合の扱いに関して調べて見たメモです。
欠測データ処理の設定
補完処理に関しては setup() のパラメータで指定されます。一覧に関しては改めてまとめるのも面倒なので、以下のようなページをご参照ください。
数値データの場合には numeric_imputation にて内挿の値を決めます。オプションは3通りで
“mean"(default)
“median"(中央値)
“zero"(0埋め)
からいずれかを選択します。
処理するデータ
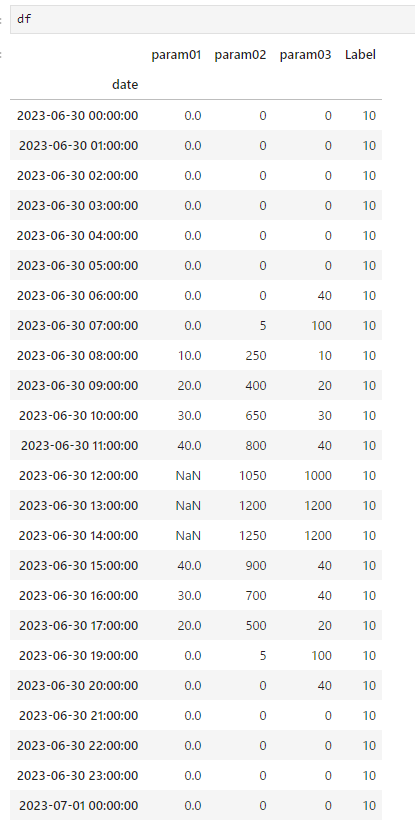
適当なデータセットを作ります。2023/6/30 12:00~14:00 の param01 が欠測している想定です。
setup()で処理した結果
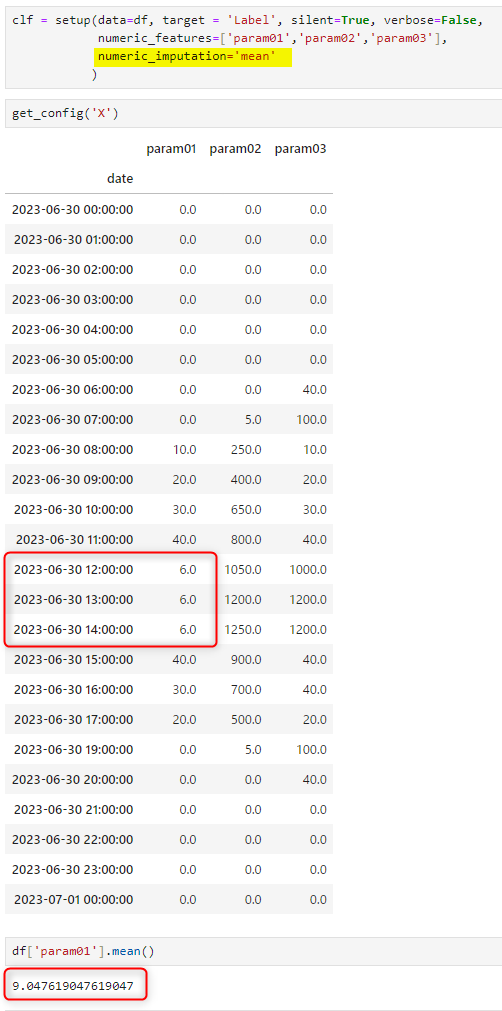
まずはデフォルトの “mean" で処理した結果です。NaNの個所に値が入っています。ただこれがmean()で計算した値とは異なるようです。(さらに言えば、setup() を実行しなおすたびに値が変わる)また、"median"に方法を変えた場合も同様に値が入ります。
タイムスタンプが存在しない場合でsetup()した場合
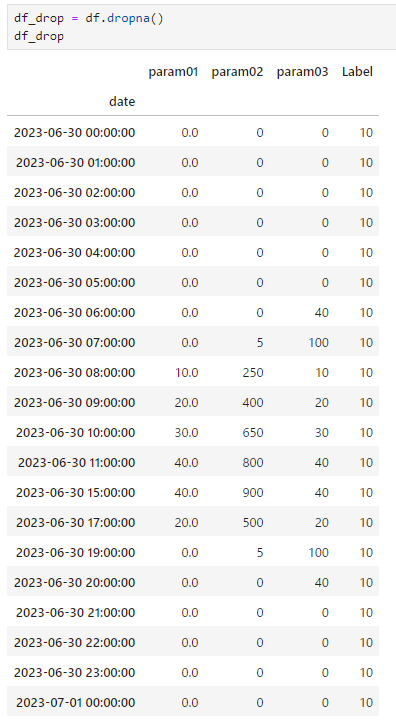
次に12~14時でタイムスタンプも無い場合のデータを準備します。
setup()で同様に処理した結果
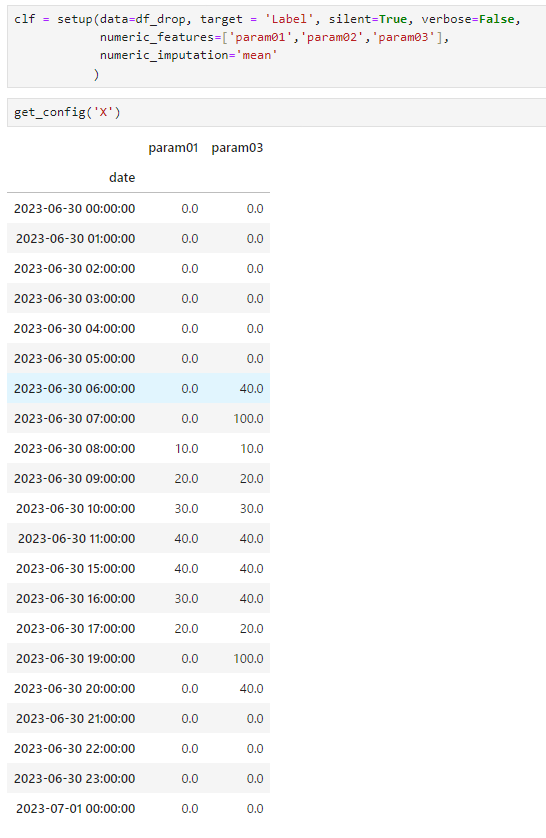
このように12:00~14:00のデータがありません。
このように
・データのタイムスタンプは記録されているものの、データが存在しない場合(NaN)は、指定の方法で補完値が代入される。
・もともとタイムスタンプが無いタイプのデータ欠損については、空いている時間を追加することは無く、単純に無いものと見なされる。(モデル構築のアルゴリズムによっては影響が出るかもしれない)
上記のような違いがありました。測器のエラーであったりデータ転送時のトラブルであったりと、欠測といってもいろいろありますので、取り扱いにはご注意を。