Twilioの音声をMicrosoftのBing Speech APIを使ってテキスト化する方法
マインドテックの冨です。
先日、Twilioのハッカソンに行ってきました。電話を使ったアプリケーションを作ろうとすると、音声をテキスト化したいニーズが出てきます。実際、Twilioにはテキスト化の機能もあるのですが、現状では日本語は対象外なんですよね。(あとテキスト化のお値段がちょっと高いw)
そんなわけでテキスト化するためには(自力で実装するのでなければ)外部のAPIを呼び出す必要があります。Google Speech APIを利用する方法は昔、高橋さんがガッツリ書いておられるので、ここではBing Speech APIを利用する方法をご紹介しましょう。サンプルはpython2.7で動作確認をしていますが、もちろん他の言語でも問題ないと思います。
ドキュメントと関連リンク
Bing Speech APIとは
https://azure.microsoft.com/ja-jp/services/cognitive-services/speech/
ドキュメント
https://www.microsoft.com/cognitive-services/en-us/speech-api/documentation/overview
Speech APIではテキスト化する音声認識と、テキストを音声データに変換する機能がありますが、ここでは前者を使います。
Microsoft Congitive Serviceのアカウントは取得しておいてください。
https://www.microsoft.com/cognitive-services/en-us/
APIキーの取得
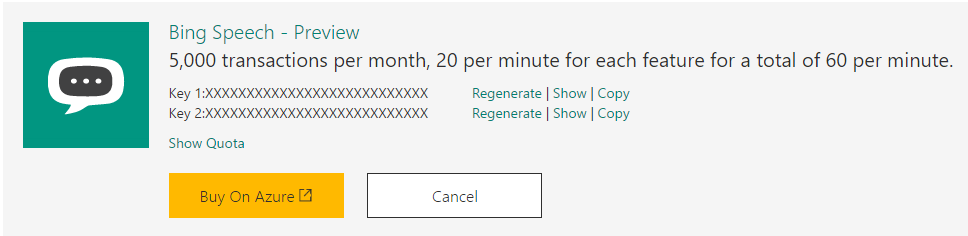
Cognitive Service の管理画面で"Bing Speech"のサービスの箇所から"key 1″をShow/Copyしておいてください。API呼び出しの際に必要になります。
認証~APIアクセストークンの取得
APIの呼び出しの際には認証が必要になります。詳細はドキュメントを参照いただくとして(笑)キーを送って認証トークンを取得します。トークンは10分間有効。
リクエストヘッダー"Ocp-Apim-Subscription-Key"にAPIキーを指定します。
Pythonでこんな感じに書きました。requestsを使ってます。
import requests
import urllib
def authorize():
url = "https://api.cognitive.microsoft.com/sts/v1.0/issueToken"
headers = {
"Content-type": "application/x-www-form-urlencoded",
"Ocp-Apim-Subscription-Key": "取得したAPIキー"
}
response = requests.post(url, headers=headers)
if response.ok:
_body = response.text
return _body
else:
response.raise_for_status()
音声変換
先に取得したアクセストークンは、API呼び出しの際にヘッダーに付与します。
"Authorization": "Bearer " + token
認証の場合と同様に、指定されたエンドポイントにPOSTでデータを投げます。
import requests
import urllib
def speech_to_text( raw_data, token, lang="ja-JP", samplerate=8000, scenarios="ulm"):
data = raw_data
params = {
"version": "3.0",
"requestid": "b2c95ede-97eb-4c88-81e4-80f32d6aee54",
"appid": "D4D52672-91D7-4C74-8AD8-42B1D98141A5",
"format": "json",
"locale": lang,
"device.os": "Windows",
"scenarios": scenarios,
"instanceid": "565D69FF-E928-4B7E-87DA-9A750B96D9E3" # from Sample Bot Framework
}
url = "https://speech.platform.bing.com/recognize?" + urllib.urlencode(params)
headers = {"Content-type": "audio/wav; samplerate={0}".format(samplerate),
"Authorization": "Bearer " + token }
response = requests.post(url, data=data, headers=headers)
if response.ok:
result = response.json()["results"][0]
return result["lexical"]
else:
raise response.raise_for_status()
“version","appid"などは指定された固定値。
“requestid","instanceid"は本当はGUIDを作成しなければいけないようですが、サンプルの文字列で動いたのでそのまま使っています(笑)きちんとしたい人は適当に直してください。
“senario"もulm, websearch などの指定が出来るようですが、違いがよく分かりませんでした。スミマセン。
端末でのテスト
これらを呼び出して実際にテキスト化してみます。適当に声を録音したwavファイルを作成します。(サンプリングレートは8000にしています。)
infile = open("sample.wav", 'r')
raw = infile.read()
txt = speech_to_text( raw , token, lang="ja-JP", samplerate=8000, scenarios="ulm")
print "text : " + txt
これで
$ python test.py text : こんにちは
こんな感じで表示されば、呼び出しはうまくいっています。
Twilioの録音音声を上記の例の"sample.wav"に相当するデータとして引き渡しできればOKです。
サーバー側のアプリ
続いて、TwiMLを返し、録音音声を取得して先のSpeech APIを呼び出すWebアプリを作成します。電話口で話した言葉をおうむ返しに読み返してくれます。
ここではpythonのBottleフレームワークを利用して、先に作成した関数も組み込んでみます。
# coding: utf-8
import sys
import os
import bottle
import requests
import urllib
import json
import commands
from bottle import route, run, post, Response, request, static_file
from twilio import twiml
from twilio.rest import TwilioRestClient
reload(sys)
sys.setdefaultencoding('utf-8')
app = bottle.default_app()
twilio_client = TwilioRestClient('TwilioのACCOUNT SID' , 'TwilioのAUTH TOKEN')
TWILIO_NUMBER = os.environ.get('(TWILIO_NUMBER)', '(Twilioで購入した電話番号)')
NGROK_BASE_URL = os.environ.get('NGROK_BASE_URL', '')
@route('/')
def index():
"""Returns standard text response to show app is working."""
return Response("Bottle app up and running!")
@post('/twiml')
def twiml_response():
response = twiml.Response()
response.say("何か話してキーを押してください。",language="ja-jp",voice="woman")
response.record(action="http://(サーバーのアドレス)/handlerecording",method="GET", maxLength="20", finishOnKey="0123456789*#")
return Response(str(response))
@route('/handlerecording')
def handlerecording():
recording_url = request.query.get('RecordingUrl')
voice = urllib.urlopen(recording_url).read()
## Authorize for Bing Speech API
token = authorize()
txt = speech_to_text( voice , token, lang="ja-JP", samplerate=8000, scenarios="ulm")
# respond TwiML
response = twiml.Response()
response.say(txt,language="ja-jp",voice="woman")
return Response(str(response))
def authorize():
url = "https://api.cognitive.microsoft.com/sts/v1.0/issueToken"
headers = {
"Content-type": "application/x-www-form-urlencoded",
"Ocp-Apim-Subscription-Key": "(API key)"
}
response = requests.post(url, headers=headers)
if response.ok:
_body = response.text
return _body
else:
response.raise_for_status()
def speech_to_text( raw_data, token, lang="ja-JP", samplerate=8000, scenarios="ulm"):
data = raw_data
params = {
"version": "3.0",
"requestid": "b2c95ede-97eb-4c88-81e4-80f32d6aee54",
"appid": "D4D52672-91D7-4C74-8AD8-42B1D98141A5",
"format": "json",
"locale": lang,
"device.os": "Windows",
"scenarios": scenarios,
"instanceid": "565D69FF-E928-4B7E-87DA-9A750B96D9E3" # from Sample Bot Framework
}
url = "https://speech.platform.bing.com/recognize?" + urllib.urlencode(params)
headers = {"Content-type": "audio/wav; samplerate={0}".format(samplerate),
"Authorization": "Bearer " + token }
response = requests.post(url, data=data, headers=headers)
if response.ok:
result = response.json()["results"][0]
return result["lexical"]
else:
raise response.raise_for_status()
if __name__ == '__main__':
run(host='(サーバーのアドレス)', port=80, debug=False, reloader=True)
(Twilioサーバー側の録音音声を削除する機能を入れてませんので、必要に応じて追加してみてください。)
TwiML取得URLの設定
Twilioコンソールで購入した電話番号の、TwiML取得URLを設定します。
電話番号>アクティブな電話番号>音声通話の"A CALL COMES IN"の欄を、上記のBottleアプリが動いているサーバーを指定します。
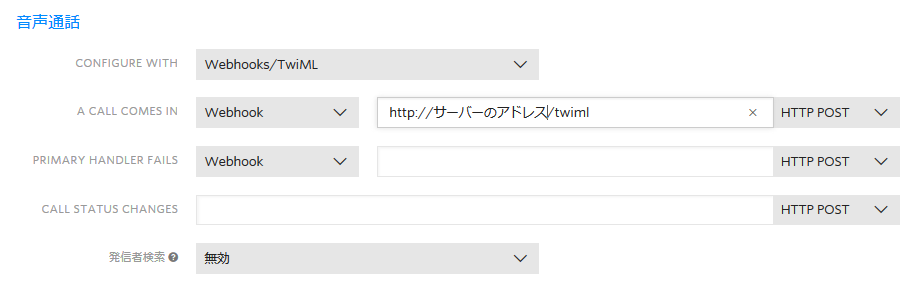
ここまでで作業は終了です。購入した電話番号に電話をかけて、ガイダンスに従って何かを話、任意のボタンを押すと、裏では”Bing Speech API"を呼び出してテキスト化し、それをTwiMLのSay動詞で読み上げを行います。上記のサンプルでお分かりの通り、Twilioの録音音声をそのまま読み込んで、Speech APIに渡せばテキスト化されてきます。特に変換は必要ありませんでした。
取得したテキストは何らかの処理に使えると思いますので、工夫してアプリを作ってみてください。(自分は同じMicrosoftのLUIS(language Understanding Intelligent Service)に送って意味解析をさせる事をやってみました。これについては改めて書こうと思います。)
ではでは。