【Python】時系列データをpandasを使って切り出す方法のメモ
時系列データを扱う際に、特定の時間帯のみを切り出したい場合や、特定の条件が合致している部分のみを抽出したい場合があります。ここでは東京のアメダスデータをPandasを利用して抽出操作を行う際のメモです。
以降、データの表示のために .head() や .tail() を付けている箇所がありますが、操作するだけであれば削除して構いません。
ライブラリとデータの読み込み
import numpy as np
import pandas as pd
%matplotlib inline
# データの読み込み
data_tokyo = pd.read_csv('./tokyo_amedas.csv', sep=',', index_col='date', parse_dates=['date'], encoding='SHIFT-JIS')
data_tokyo = data_tokyo.dropna()
print(type(data_tokyo.index))
data_tokyo.head()
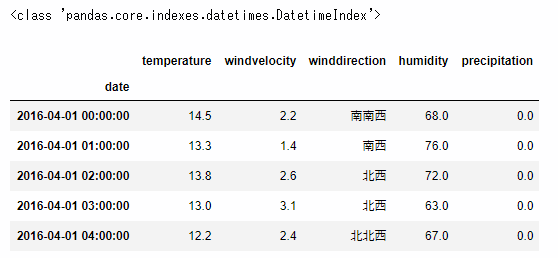
インデックスが"DateTimeIndex"になっています。それぞれの項目は気温、風速、風向、湿度、前1時間降水量です。
日時で絞り込み
between_time()を使って、特定の時間帯だけを絞り込めます。
data_tokyo.between_time('2:00', '4:00', include_end=True).head(10)
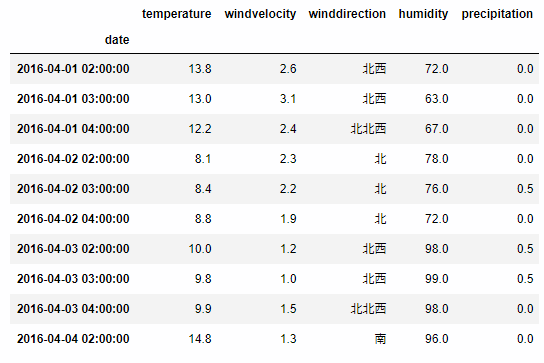
毎日の2:00, 3:00, 4:00のデータが選択されている事が分かります。
.loc を使って、指定の月を絞り込めます。
data_tokyo.loc['2018-2':'2018-4'].tail()
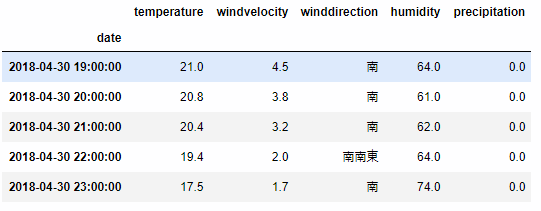
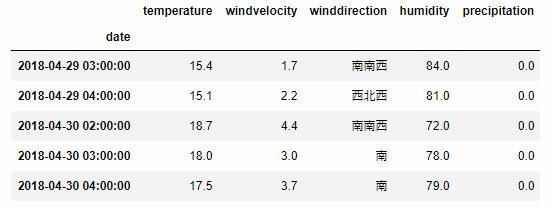
これらを組みあわせて、指定した月の指定時間帯を絞り込むことが出来ます。
data_tokyo.loc['2018-2':'2018-4'].between_time('2:00','4:00', include_end=True).tail()
値が条件に合致する場合の絞り込み
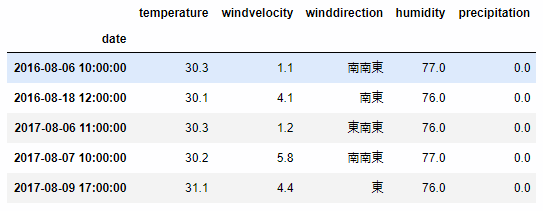
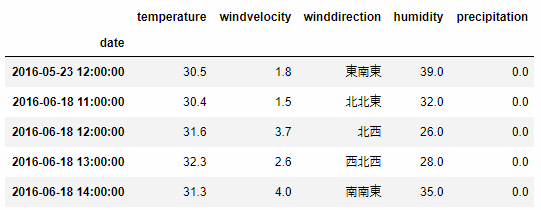
気温が30度を超える夏日の条件を指定します。
data_tokyo[ data_tokyo['temperature'] > 30 ].head()
.query() を使うと、複合条件を指定できます。気温が30度を超え、かつ湿度が75%を超える条件を指定します。
data_tokyo.query('temperature > 30 and humidity > 75').head()