PowerPointからエクスポートしたPDFで文字コードが変わった件
講習会の資料でソースコードを記載したPDFを配布したところ、コードをコピペして動作確認しようとした際に動かない事象が発生。
具体的な話ですが、文字列をコンソールに表示する際などで、改行を"\n"と記載する場合があります。
これを含むコードをオリジナルのPPTファイルからコピペした場合は問題なかったわけですが、PPTからPDFにエクスポートしたファイルからのコピペでは動作が表示がおかしくなりました。改行されるべきところで "\n"がそのまま表示されたのです。
調べてみたところ、サクラエディタ―に貼ってコードを調べた所、オリジナルは U+005C(バックスラッシュ)でしたが、PDFからコピペしたものは U+00A5 (YEN SIGN)になっておりました。
WindowsがUnicode化する際に、U+005Cはバックスラッシュだが、表示では円マークにしている事から混乱が起こりがちなのですが、コピペした際にコードが変わってしまうのは困るんですよね。見た目が一緒なのでレビューをしてもミスと分からないのですよ。
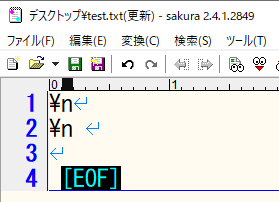
上が U+00A5 で下は U+005C です。判別つくはずもなく・・・